TL;DR
4DNeX is a feed-forward framework for generating 4D scene representations from a single image by fine-tuning a video diffusion model. It produces high-quality dynamic point clouds and enables downstream tasks such as novel-view video synthesis with strong generalizability.
Interactive Demo
Generated Video
Generated 4D Scene








Abstract
We present 4DNeX, the first feed-forward framework for generating 4D (i.e., dynamic 3D) scene representations from a single image. In contrast to existing methods that rely on computationally intensive optimization or require multi-frame video inputs, 4DNeX enables efficient, end-to-end image-to-4D generation by fine-tuning a pretrained video diffusion model. Specifically, 1) To alleviate the scarcity of 4D data, we construct 4DNeX-10M, a large-scale dataset with high-quality 4D annotations generated using advanced reconstruction approaches. 2) We introduce a unified 6D video representation that jointly models RGB and XYZ sequences, facilitating structured learning of both appearance and geometry. 3) We propose a set of simple yet effective adaptation strategies to repurpose pretrained video diffusion models for the 4D generation task. 4DNeX produces high-quality dynamic point clouds that enable novel-view video synthesis. Extensive experiments demonstrate that 4DNeX achieves competitive performance compared to existing 4D generation approaches, offering a scalable and generalizable solution for single-image-based 4D scene generation.
Method
Given an initialized XYZ map, 4DNeX encodes both inputs using a VAE encoder and fuses them via width-wise concatenation. The fused latent, combined with a noise latent and a guided mask, is processed by a LoRA-tuned Wan-DiT model to jointly generate RGB and XYZ videos. A lightweight post-optimization step recovers camera parameters and depth maps from the predicted outputs, yielding consistent dynamic point clouds.
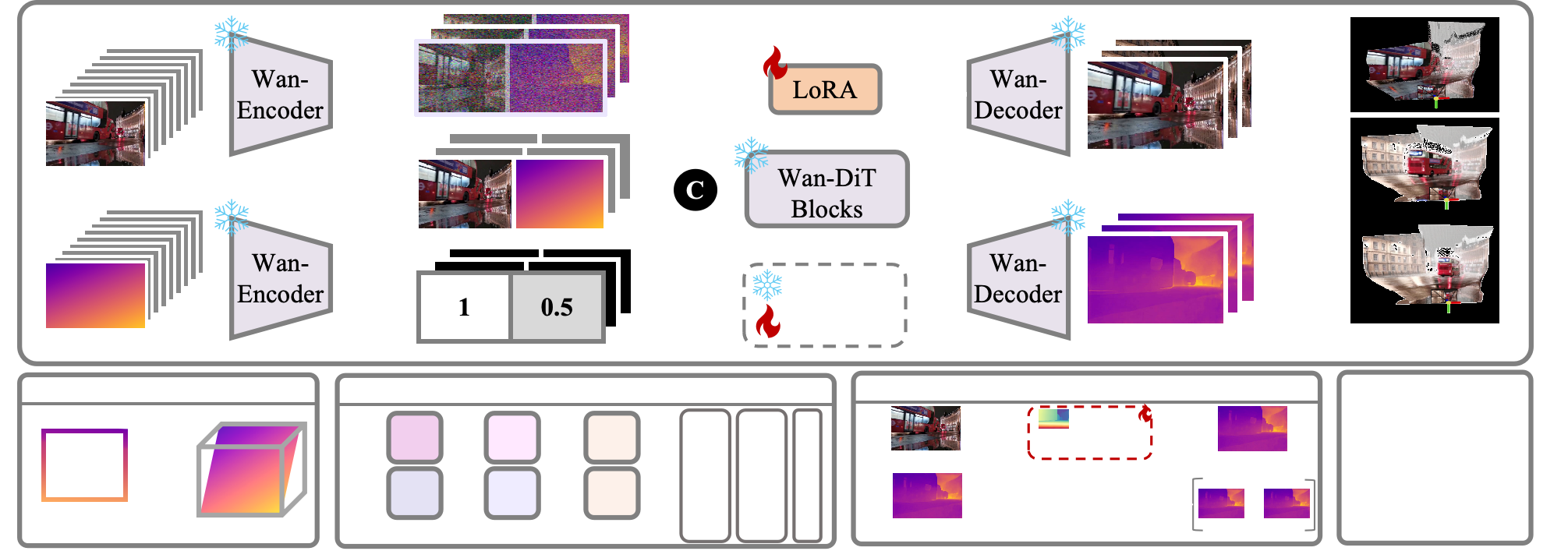
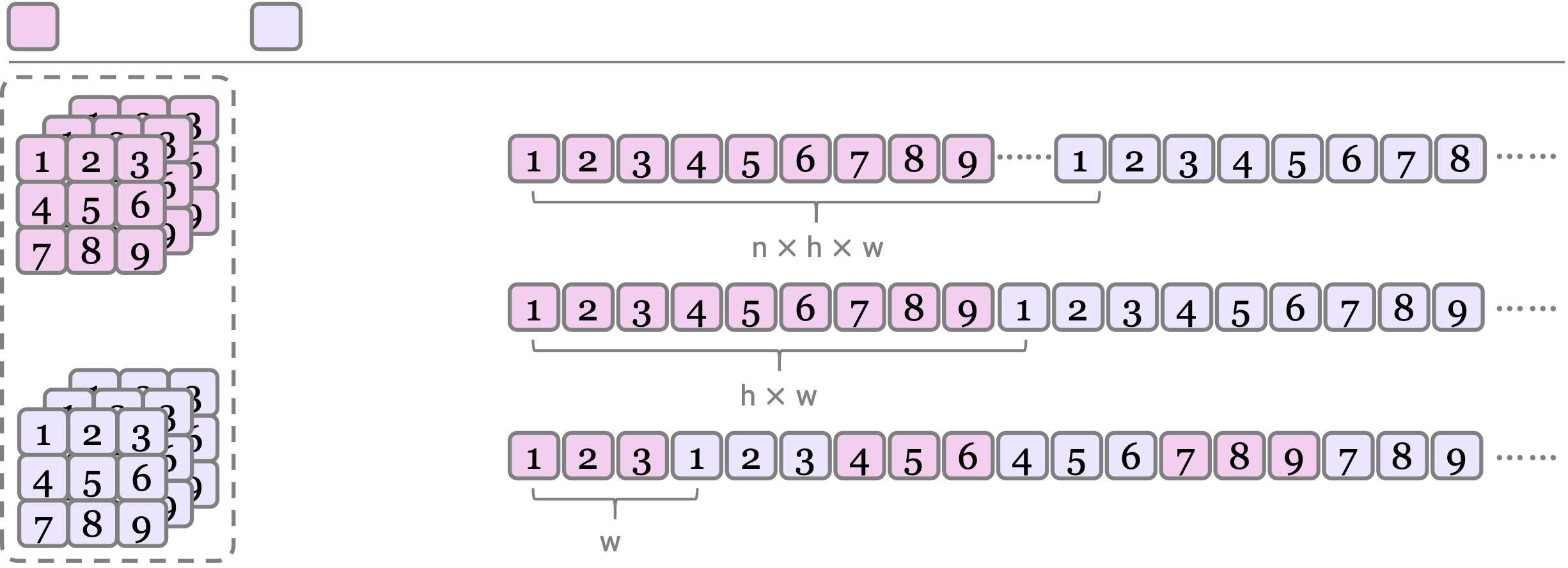
Fusion Strategies
We explore five fusion strategies to combine RGB and XYZ inputs:
- (a) Channel-wise: Breaks pretrained distribution; often fails to generate meaningful outputs.
- (b) Batch-wise: Preserves unimodal quality but lacks RGB-XYZ alignment.
- (c) Frame-wise: Keeps temporal order but weak cross-modal interaction.
- (d) Height-wise: Slightly better alignment, still suboptimal.
- (e) Width-wise: Brings RGB and XYZ tokens closer, enabling coherent joint generation.
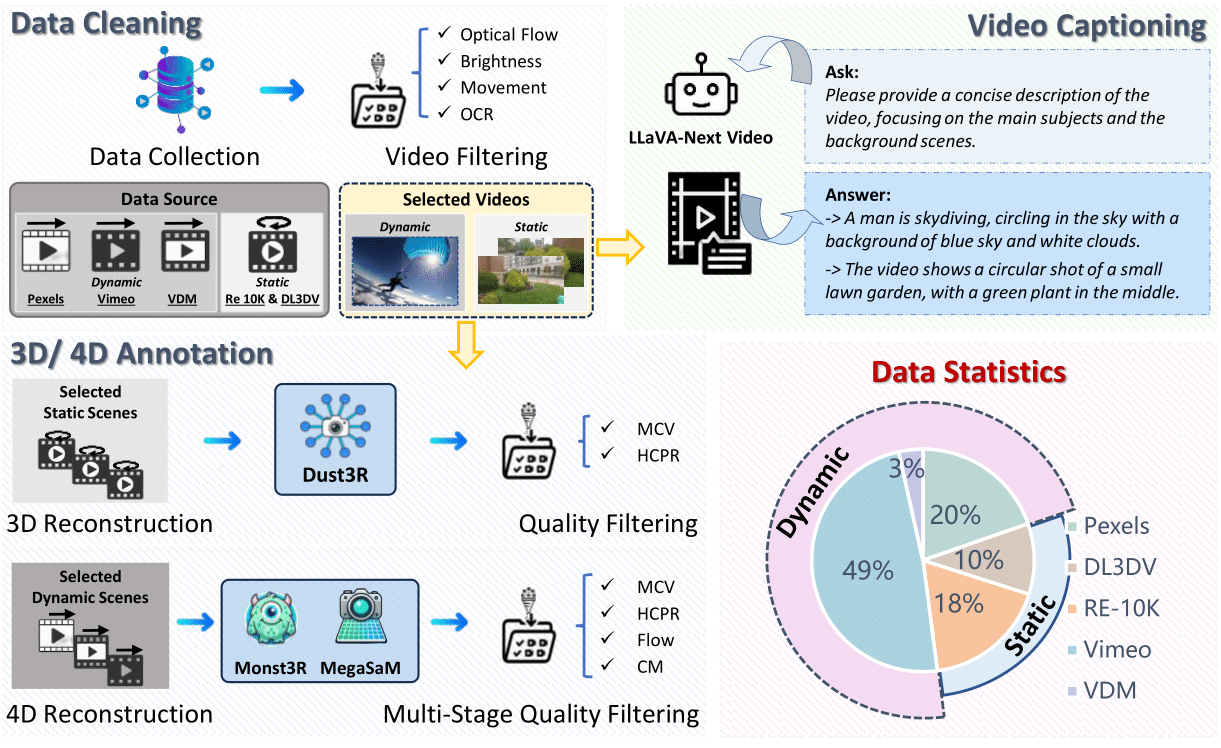
Dataset
We present 4DNeX-10M, a large-scale dataset with over 10 million frames across diverse static and dynamic scenes, including indoor, outdoor, close-range, far-range, high-speed, and human-centric scenarios. Pseudo-4D annotations are generated using off-the-shelf reconstruction models, followed by multi-stage filtering to ensure geometric accuracy and scene diversity.

Results - 6D (RGB+XYZ) Video
4DNeX generates paired RGB and XYZ sequences, forming a unified 6D representation of dynamic scenes.
Results - Dynamic Point Cloud
The generated 6D (RGB + XYZ) videos can be lifted into dynamic point clouds.
These dynamic point clouds can be visualized interactively.
Results - Novel-view Video
The generated dynamic point clouds empower downstream applications such as novel–view video synthesis.
BibTeX
@article{chen20254dnex,
title={4DNeX: Feed-Forward 4D Generative Modeling Made Easy},
author={Chen, Zhaoxi and Liu, Tianqi and Zhuo, Long and Ren, Jiawei and Tao, Zeng and Zhu, He and Hong, Fangzhou and Pan, Liang and Liu, Ziwei},
journal={arXiv preprint arXiv:2508.13154},
year={2025}
}